Introduction
This is my reading notes for Gao et al’s Neural Approaches to Conversational AI. I just marked something I think is important and made the structure more logistic clear. Since I just read the paper once, there must be something that I wrongly understood. Feel free to contact me at haroldliuj@gmail if you find something wrong. Have a nice trip!
Dialogue Hierarchical Structure
- There is a top-level process selects which sub-process should be called.
Neural NLP Tasks
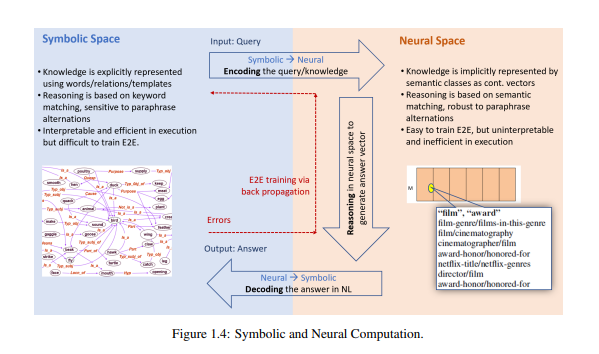
3 Common Steps
- Encode symbolic space to neural space
- Reasoning in neural space
- Decode neural space to symbolic space
CH2 Reinforcement Learning
Challenges of RL
- Exploration-exploitation tradeoff
- Delayed reward and temporal credit assignment
- Partially observed states
Foundations
Markov Decision Process
- Denotes

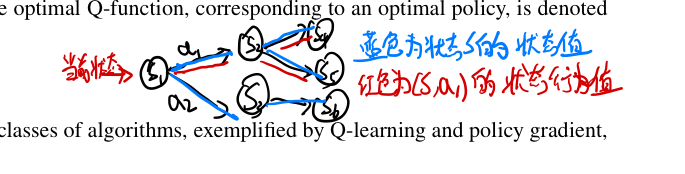
Basic Idea

Policy $\pi = P(A=a|s=s_t)$ stands for the policy that the agent can adapt.
Once we choose the policy, we can compute the reward:
However, since $\pi$ is a possibility distribution, we can not use $G_t$ directly as the final score, because is different each time we compute it. So we use expected value as our score. So we will define 2 scores, the value of the state and the value of the state with action
The Value of the State:
The Value of the State with Action
Difference between those 2 eqns above:
Q-Learning
Basic Idea
Since we use Q to represent how good the policy can be, so we can find the max Q so that we can find the best policy.
Q-Learning : Use “Temporal Difference” to update gradient:
Policy Gradient
- The policy $\pi$ itself is directly parameterized by $\theta \in \R^d$
CH3 QA & Machine Reading
Steps for KB-QA
- Semantic Parsing
- Multi-Step Reasoning
Semantic Parsing for KB-QA
1. Embedding-based Methods
Same as word vectors, semantic vectors are encoded via knowledge base completion, that is, to recognize whether a triple is in KB
We can compute the score for a triple to mark how likely the triple will exist in KB:
$score(s,r,t;\theta) = x_s^TW_rx_t$
where $x_r$ is the semantic vector. The model will learn $x$ and $W$ simultaneously
Multi-Step Reasoning on KB
Since not every relation for two entities is represented in KB, we need some way to infer the relations between two entities with the relations we have.
1. Symbolic Methods —- Path Ranking Algorithm(PRA)
Random walk in KB and find some possible path
When given a query $q=(s,r,?)$, search the path that may suitable for $r$, denoted as $B_r=\{\pi_1, \pi_2…\}$
Travel those paths and find the candidate target $t$
Compute the score of $t$
$score(q,t) = \sum_{\pi \in B_r}\lambda_\pi P\{t|s, \pi\}$ where $\lambda_\pi$ is the learned weight
2. Neural Methods —- Implicit ReasoNet
Intuitive Idea: tell algorithm, “Hey, you should pay some attention on here in KB” for many times
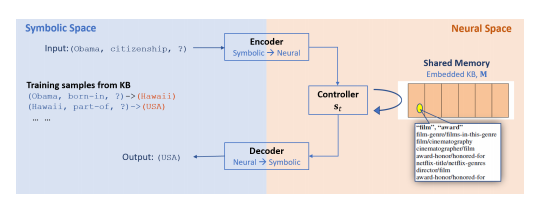
Encoder: Encode $s, r$ into semantic vector space
Shared Memory $M$: Each vector represents a concept, is embedded from KB
Controller: A RNN with attention
- Compute the how much attention the current state $s_t$ should pay on each concept in $M$
- Compute weighted memory as input of next time step
- Compute next state $s_{t+1}$
Conversational KB-QA Agent
1. Common Architecture
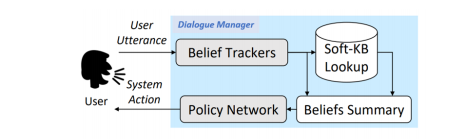
- Belief Trackers:
- Resolving coreferences and ellipsis in user utterances using conversational context
- Identifying user intents
- Extracting associated attributes
- Tracking the dialogue state
- Interface with KB to query for relevant results
- Beliefs Summary: Summarize the state into a vector
- Dialogue Policy: Selects the next action based on the dialogue state.
Machine Reading for Text-QA
1. Common Architecture
Lexicon Embedding Layer: Maps each word to a vector space using a pre-trained word embedding
Contextual Embedding Layer: Utilizes contextual cues from surrounding words to refine the embedding of the words
- e.g. bank of a river vs bank of America
Attention Layer
- Compute attention for Passage through Questions
Reasoning Layer
Single-Step Reasoning
Summarizing question vector:
Predict start position:
Predict end position:
The idea here is integrating question and the answer start position info to predict the end position.
$\mathbf{M}$ is shared semantic info
Multi-Step Reasoning
The idea is the same as the single-step reasoning, while multi-step can compute the start and end position over $T$ memory steps and get t start position and end position possibilities with attention. Finally compute the average value of those position possibilities as the final prediction.
At Each time step t:
CH4 Task-oriented Dialogue Systems
Task-oriented Dialogue is also called slot-fitting, that is there are some predefined slots(essential info that used to finish the task. e.g. num of tickets, departure date for ticket booking) by the domain expert and the goal of the task is to get the information from users and fill the slots so that the system can finish the task. There are two kinds of slots:
- Inform able slots: the value for this slot can be used to constrain the conversation, such as phone number;
- Request able slots: the speaker can ask for its value, such as ticket price.
Common Architecture
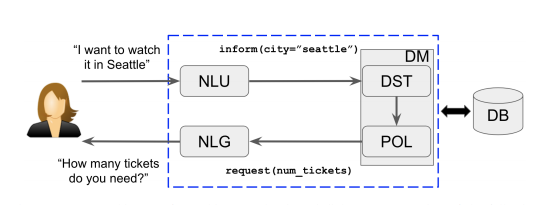
- Natural Language Understanding(NLU): Takes user’s raw utterance as input and converts it to the semantic form of dialogue acts.
- Dialogue Manager(DM): The central controller of the system, this module will decide whether the system will interact with the user or with the DB
- Dialogue State Tracking: track the current dialogue state
- Dialogue Policy
- Natural Language Generation(NLG): If the policy chooses to respond to the user, this module will convert this action
Evaluation
Categories
task success rate
cost of dialogue
OR
simulation based
human based
Natural Language Understanding
1. 3 Tasks
- Domain detection(classification task)
- Intent determination(classification task)
- Slot tagging(bidirectional LSTM)
ps: In most cases, they are trained separately while it can be more cost-saving if we train this model jointly
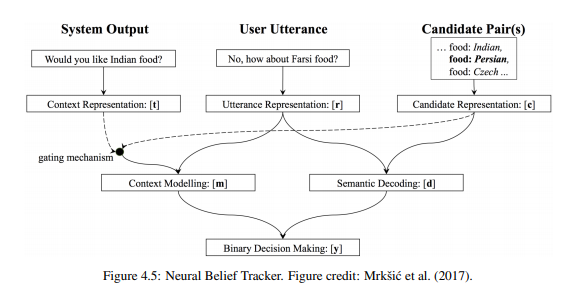
Dialogue State Tracking
Dialogue state contains all information about what the user is looking for at the current turn of the conversation.
A example Neural Belief Tracker
Dialogue Policy Learning
1. RL Method
Train a Fully Connected Neural Network to find the Q-Function so that we can use the action correspond to the maximum Q-value to make our decision.
- Input $\mathbf{s}$ contains:
- one-hot representations of the dialogue act and slot corresponding to the last user action;
- the same one-hot representations of the dialogue act and slot corresponding to the last system action;
- a bag of slots corresponding to all previously filled slots in the conversation so far;
- current turn count
- the number of results from the knowledge base that match the already filled-in constraints for informed slots
- Output $\mathbf{q}$ is the predicted Q-Values for corresponded actions
Since training a network from zero can use great amount of data, we can use warm start policy to pretrain the network
Besides, RL agent should explore and extend slots over using, so we should introduce domain extension tech
2. Policy Learning for Composite-task Dialogues
Composite-task
- User will ask the machine to finish a series of tasks that are correlated to each other. That is, there are cross-subtask constraints(e.g. the hotel check in time should be later then the plane arrival time)
2 ways to resolve:
Hierarchy Ways: Top level policy will decide with sub-level policy to use
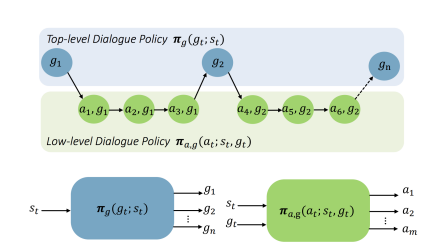
Feudal Reinforce Leaning: The policy will first decide whether to gather more info or provide info to user, then choose corresponding actions.
3. Policy Learning for Multi-Domain Dialogues
- Multi-Domain Dialogues
- There are no cross-task constraints but it still have to maintain a large dialogue states
- 2 Ways to resolve:
- Train many policies, then vote for action
- Train many policies which are asked to finish different subtasks and train a picker to decide which policy to use.
4. Integration of Planning and Learning
- Planning: Learn from simulator
- Learning: Learn from real user
- Use different weights for simulator and real user
5. Reward Function Learning
- Hand write
- Neural network method(may be better than hand write functions)
CH5 Fully Data-Driven Conversation Model and Social Bots
End to End Conversation Models
1. HRED
To exploit longer-term context
Two-level hierarchy structure that combine 2 RNNs:
- One at a word level
- One at the dialogue turn level
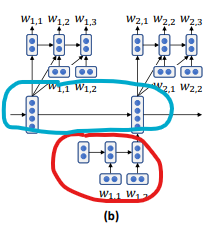
Use this extra dialogue turn level to capture context in conversation level rather than just word level
2. Attention Models
- Less effective in E2E dialogue modeling
3. Pointer-Network Models
The basic idea is to use what has been shown in the context(“Copy and Paste”)
- produces an output sequence consisting of elements from the input sequence:
- drawn from a fixed-size vocabulary
- selected from the source sequence
Challenges and Remedies
1. Response Blandness
- The agent will tend to response something less informative such as “I don’t know” for all questions
- Remedies:
- Maximum Mutual Information
- Hard to optimize, so just use it at inference time
- Just can mitigate rather than completely eliminates the blandness probles
- GAN
- VHERD
- Use retrieval-based method
- Hard to extend
- Maximum Mutual Information
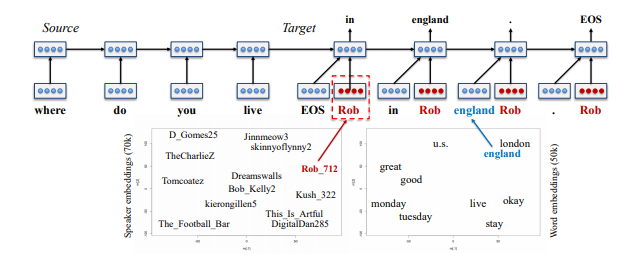
2. Speaker Consistency
Let agent reply with a consist personality
Methods:
Combine word vectors with speaker embeddings
3. Word Repetitions
- Remedies:
- Self-attention
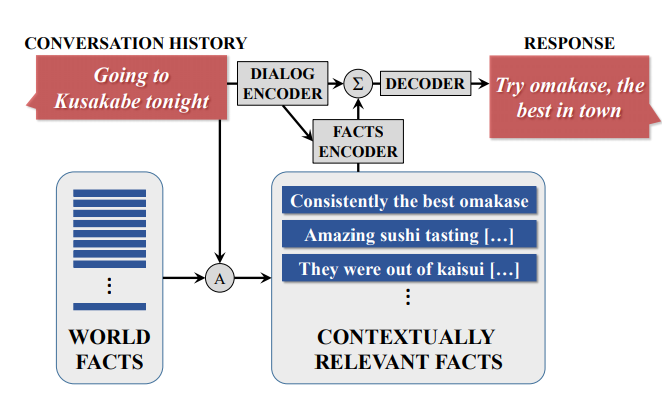
Grounded Conversational Models
- Let chatbot response base on real world information rather than what is in the training data
- Train an extra Facts Encoder to encode real world info
Reinforcement Learning Can Make Better Results
Need to find reward function since normally there is no clear goal for users when they are making chitchats
Example of reward function, has 3 components:
- $-p(\mathbf{Dull\ Response} | T_i)$: to penalize noninformative response
- $-log\operatorname{Sigmoid cos}(T_{i-1}, T_i)$: to ensure that every response should contain some new information
- $lopp(T_{i-1}|T_i) + logp(T_i|T_i-1)$: to counterbalance the aforementioned two rewards
References
- Gao J, Galley M, Li L. Neural approaches to conversational AI[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1371-1374.